
Vibe Analysis
AI is coming for data analysis, and it will never be the same

Vibe coding is for creating software. Vibe analysis is for creating insights.
Vibe analysis could be an even bigger deal: there are about 2 million software engineers in the US, but at least 5 million people who use data to answer questions every day.1
That means that in the US alone, we’re spending 10 billion hours a year reporting on business performance, assessing new products and features, and deciding which experiments to ship and which growth opportunities to pursue.
I worked with some of the team at Faire who are at the edge of applying AI to analytical work — Alexa, Ali, Blake, EB, Jolie, Max, Sam, Tim, and Zach — to shed light on the change that is coming.
We’ll look at both the bull case (how AI could massively increase the efficiency and quality of data analysis) and the bear case (why it will be harder than many people think).
What becomes clear is that no matter how conservative your assumptions, within a few years the way analysis is done and who does it will be unrecognizable from today.
The bull case
Data analysis is full of the kinds of things that humans are bad at and machines are great at. There are basically four components.
The hardest part is often simply knowing what data to use - understanding the schema, how different tables and fields interact, and what is up to date. If you hook up ChatGPT to a data warehouse today, you get a tool that is pretty dumb out of the gate but gets smart quickly as it develops a semantic model of the dataset2. Instead of asking each team member to learn this for themselves, you can ask a model to learn it once.
Another component of analysis is writing SQL queries themselves. This is such an obvious use case that off-the-shelf LLMs are already very helpful at quickly cleaning up and generating queries. Cursor is pretty good at it too. Products that are purpose-built for data analysis will be excellent at it.
The third component is manipulating data into a useful format. Some of this can be done through the query, but many forms of analysis require a secondary tool like spreadsheets. New solutions for this are exploding, such as the viral launch of Shortcut (a “superhuman Excel agent”) just a few weeks ago.
Finally, there is visualizing and dashboarding data. This is probably where the tools are weakest today, but there are sparks of genius. All of the charts below were one-shotted by Claude based on some data and a quick description of the format:
As incumbents and startups race to build solutions to these problems, two distinct UIs are emerging:
“Cursor for analytics” where the core workflow is autocomplete, editing, or refactoring of existing code. Startups like NAO and Galaxy are building for this use case and incumbents like Mode are incorporating it into their products.
“Data chatbots” where the core workflow is natural language conversations that output basic datasets and charts. Many incumbents are building this, including Snowflake and Looker.
Today the former is accessible only to more sophisticated users, and the latter just have very limited capabilities. There are strong incentives for a tool that does both, because this would allow the work of power users to tune the semantic model for the benefit of everyone else.
This tool will also need built-in visualizations in order to avoid analysts constantly jumping between workflows, and to enable static dashboards and charts for sharing.
The space is begging for a full stack solution which:
Is native to your data warehouse and holds as much of it in context as possible
Constantly updates its semantic model of the data schema as it is used
Provides data and visualizations by default, but exposes SQL to those who want it
Has a built-in visualization tool that allows rapid iteration on charts
A product like this would supercharge analysis, collapsing the time it takes by 5x or more. There would no longer be distinct steps required to figure out what tables to use, write a query, slice the data, and visualize. You could just… talk to your data. You could vibe with it in the same way Karpathy imagined vibing with code
It wouldn’t stop there. Give a tool like this access to email, Slack, and Notion, and now it can learn not only what analysis gets done but what action it leads to. It would be a context sponge for how the business is performing and what is working and not working.
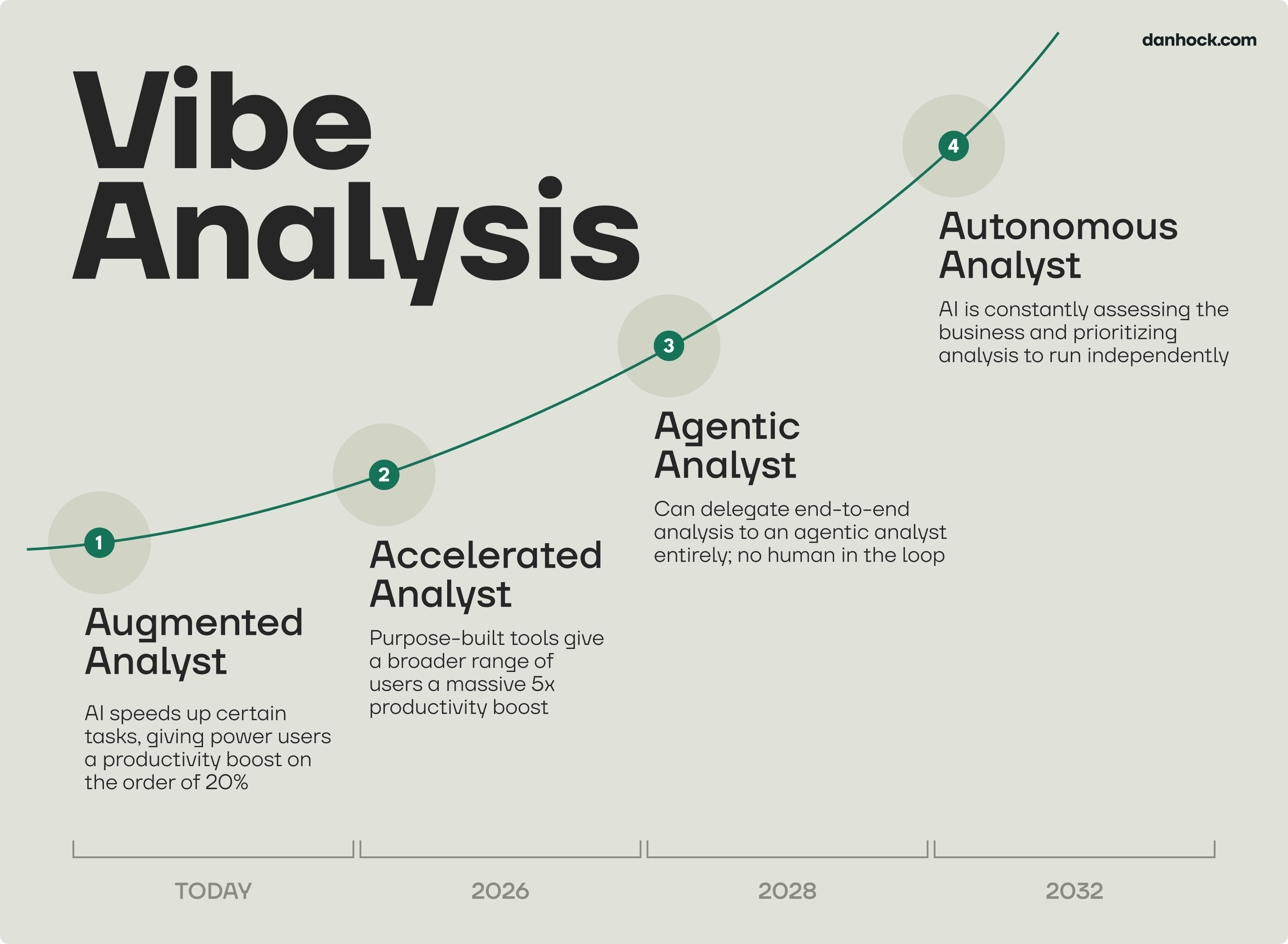
It would put us on a path that looks something like this:
Augmented Analyst - This is where we are today. AI is speeding up certain tasks, providing power users a productivity improvement on the order of 20%.
Accelerated Analyst - End-to-end tools like the one we describe above arrive. Analysis speeds up by 5x or more and is accessible to many more people.
Agentic Analyst - You can delegate a basic end-to-end analysis to an agent entirely - no human in the loop.
Autonomous Analyst - Instead of assigning analysis to an agent, it constantly assesses the business and prioritizes analysis to run on its own.
All of the pieces needed to achieve the Accelerated Analyst phase are in place, we just need to build the products and test them inside companies. A 1-year timeline to get to a reasonable product in the wild is feasible.
From there, I will borrow the timelines proposed by Dwarkesh Patel, which are significantly more conservative than something like AI 2027. He outlines two milestones:
2028: ability to complete an end-to-end knowledge work tasks of moderate complexity. This maps to the Agentic Analyst phase.
2032: “continuous learning” ability (the product can accumulate tacit knowledge, refine approach, and internalize feedback). This is the point at which the AI is acting autonomously.
The Vibe Analysis timeline:
The bear case
There is just one problem: real analysis is a lot messier than we’ve been describing.
The example that Dwarkesh gives of an end-to-end knowledge work task that AI could do by 2028 is filing taxes for a small business. That activity is guided by a set of rules and has an output that is verifiably accurate.
Most data analysis is neither of those things — it’s an exploration of an undefined problem space with an undefined range of outcomes. This means that (1) the actual efficiency gains will be lower in the Accelerated Analyst phase and (2) it will take longer to get to the Agentic Analyst phase.
So far we’ve only been talking about the part where you’re pulling or manipulating data — the “analysis” itself. But to actually go all of the way from question to insight requires a bundle of four things, and machines are less good at the other parts.
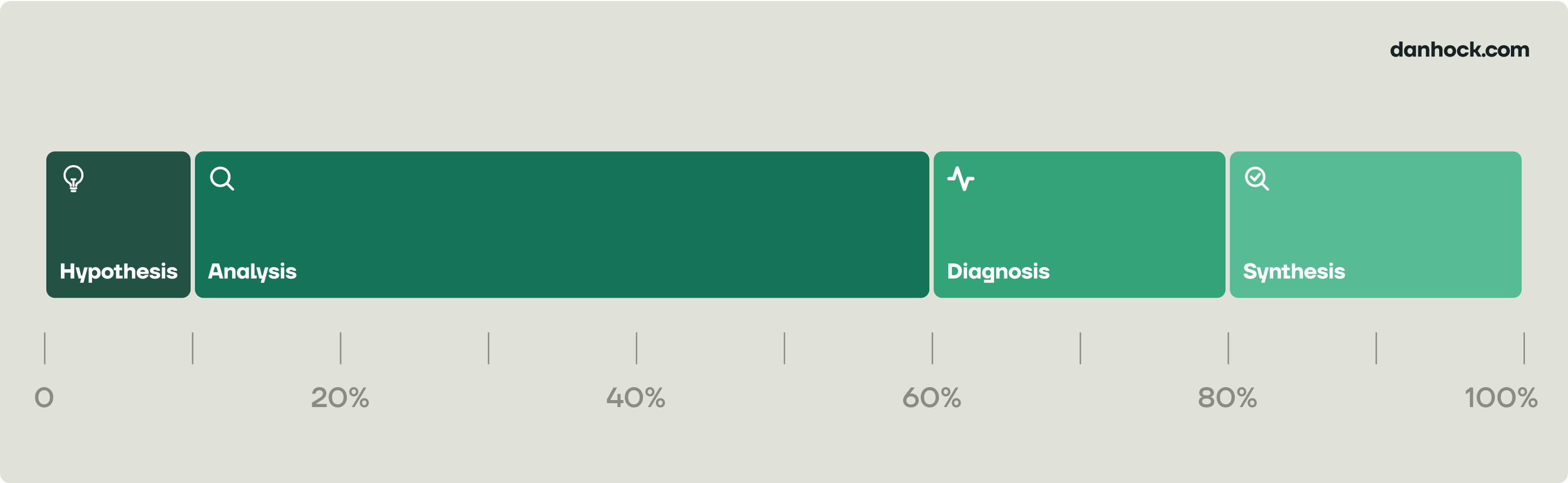
Hypothesis is the phase at the beginning where you use accumulated context and intuition to answer the question “what do we expect the answer or range of possible answers to be”? It’s maybe 10% of the total amount of time spent, but a huge amount of the leverage.
Diagnosis is where you apply everything you’ve learned from the data to form “the answer”. It is probably 20% of the time investment today.
Both of these will be highly resistant to change. They require the generation of novel ideas, which is a particular weakness of the current generation of AI products. Certainly tools today can help with this, for example by generating an exhaustive list of possible answers or pressure testing the best ones. And if the core constraint here is simply “context”, won’t models get better as they learn more and more about your company? Probably. But let’s be hyper conservative and say that these two steps don’t get more efficient at all.
Synthesis is the phase at the end where you put everything into a format that is clear, structured, and can be shared, like a doc or a presentation. This is the final 20% of time spent today.
Part of creating a final document is actually clarifying your understanding of the problem. Writing is thinking, and that piece won’t get much faster with AI. But there is also a big part of it that is simply a “clean-up” effort to structure and trim the doc, make it easy to read, and ladder supporting insights under each claim. If AI is great at one thing, it is great at summarization. It will become trivially easy for it to generate a doc in whatever format and level of depth you want.
At Faire we built a custom GPT with templates, examples, and writing principles that can translate a rough “answer” into a full output doc, and help you improve that doc over a few iterations. This will get much better as more specialized tools are built for this purpose. It’s relatively conservative to say that synthesis will get about twice as fast.
If you’re keeping score, we’ve said that:
The analysis phase gets 5x faster (not automated)
Synthesis gets twice as fast
Hypothesis and diagnosis don’t change at all
Even with these relatively conservative assumptions, we’re talking about speeding up the entire process by 2x and significantly shifting the composition of work away from technical data skills and toward judgement, intuition, and communication.
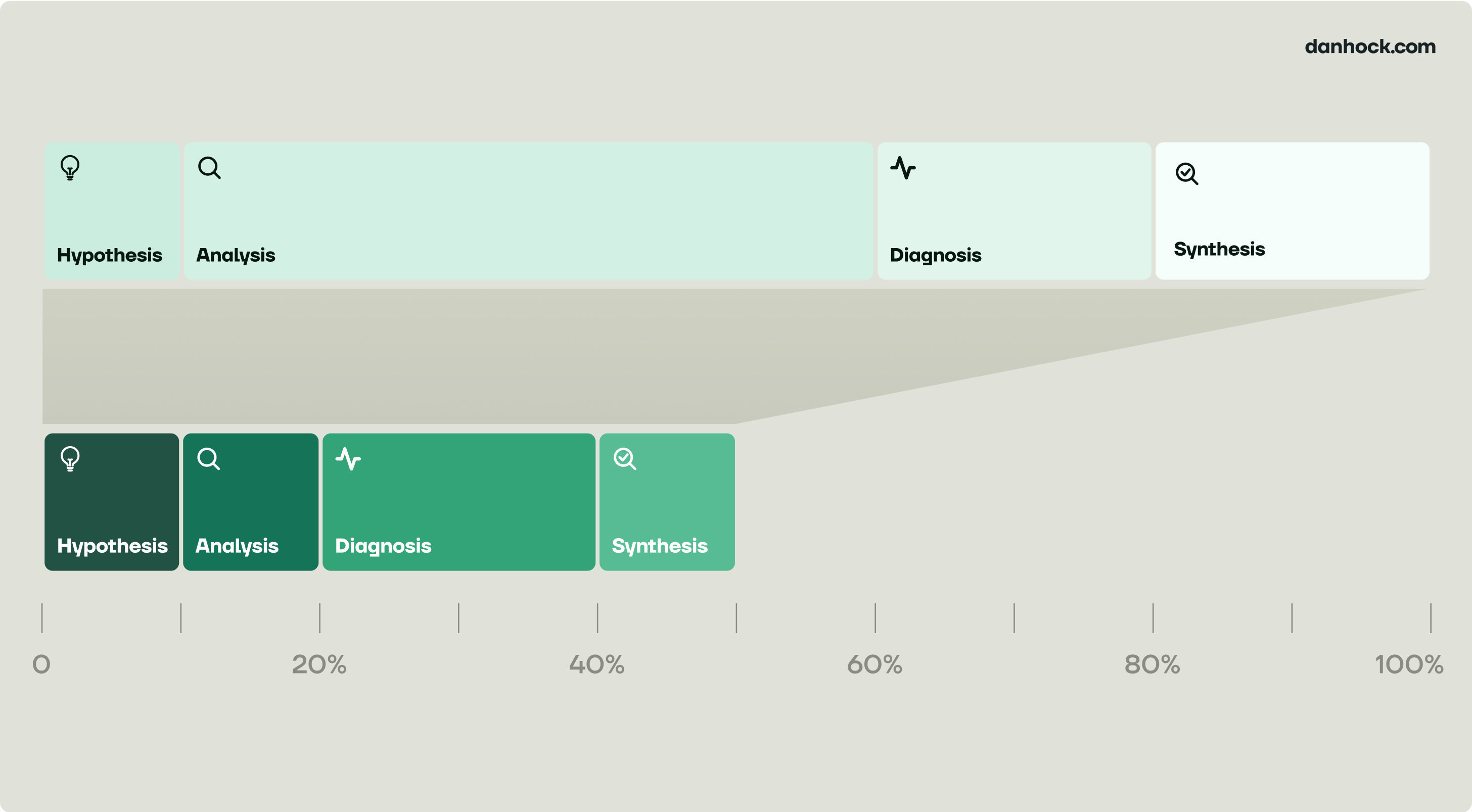
Some kinds of analysis will collapse even more, depending on how much judgement they require. On one end of the spectrum you have more rote analysis like analyzing the results of an experiment or generating a weekly performance report. On the other end you have the assessment of a greenfield expansion opportunity or figuring out which teams to resource.
While the latter requires a lot of judgement, it’s possible that AI could compress the former by much more and get to the agentic state faster.
Predictions
No matter how conservative you try to be, it’s clear that analysis is going to change a lot, and that this will probably happen inside of five years. What does that mean?
Analysis will decentralize
Tools like Looker, Sigma, and Mixpanel promised to democratize data by abstracting SQL and letting anyone play with drag and drop UIs. But they all tended to be limited to certain datasets, applicable mainly to standardizable parts of a product like growth funnels, and quite brittle and time-intensive to maintain.
AI tools will deliver on this vision for real. Anyone will be able to just talk to the database and get an answer. Many more people will do analysis, much more often. The CEO will be able to understand how a new product is performing in just a few minutes. Any salesperson will be able to generate a report to close a new prospect on the fly. Engineers might (gasp) not need to talk to a product manager to figure out what to build next.
The role of analyst will transform
When hiring analysts today, companies are looking for both technical skills and strategic judgement. It’s possible but very difficult to find people that are excellent at both. A lot of companies give up and hire analysts who spike on technical skills but lack judgement, and rely on product managers or others to “be strategic”.
As the more technical parts of the job are abstracted, the purely technical analyst will become significantly less valuable. Analysts will be hired primarily based on their ability to apply judgement and answer hard questions.
In the process, analysts will become massively more impactful. We will start to see “super ICs” that can do the work that a manager and team of 6-7 people used to do.
I suspect this will not mean fewer analysts, just that their collective output is much greater. Jevons Paradox (which says that increased efficiency of resource use often leads to more consumption of that resource, not less) is very much at play. I’ve never seen a company run out of questions to ask.
Companies will grow faster
All companies are effectively trying to turn this flywheel as fast as possible:
They are learning about their customers, the market, and how the product is performing. Then they are using these insights to build and sell new things. Repeat.
As AI makes engineers more productive and code less scarce, the constraint on the right side of this flywheel is lifting. The bottleneck is now on the left side.
In a world where you can generate insights twice as fast and many more people can do it, this whole flywheel can again get unstuck. Vibe analysis will accelerate the rate at which companies learn, and thus how fast they can grow.
There are roughly 3-4 million “pure play” data analysts in the US, including the following job categories: data analysts, business intelligence, data science, market research analysts, operations research analysts, management analysts, financial analysts, business operations analysts, marketing analysts, product analysts. This doesn’t include the many millions of people in professional services, product, marketing, sales, operations and corporate functions that use data as part of their everyday toolkit. It’s a lot.
Here’s ChatGPT explaining how its integration with Faire’s data works:

Totally agree that semantic modeling is the single biggest hurdle for 'autonomous analysts'. We've been working on automating that layer and just released a fully functioning beta version of our approach: https://www.connectyai.com/blogs/the-future-of-metrics
Would genuinely love your thoughts!
Great post. Where does Amplitude fit in with their new agent offering in beta?